Workflow for deposits
This page provides information about creating and managing deposits using the REST API of the Data Repository service. All requests are made using Python.
General publication workflow
The HTTP REST API does not impose a specific workflow for creating a deposit, but some steps need to be taken in order independently from each other. The following example workflow only defines the most basic steps:
Identify a target community for your data by using the REST API List all communities request
Using the community’s identifier, retrieve the JSON Schema of the deposit’s metadata. The submitted metadata will have to conform to this schema. Use the Get community schema request.
Create a draft deposit: use the Create draft deposit request.
Add and update metadata of the deposit: use the Update metadata of draft deposit request.
Upload files into the draft deposit. You will have to use one HTTP request per file. Use the Upload file request.
Set the complete metadata and publish the deposit. Use the Submit draft for publication request.
Preparation
When your dataset is ready for publication, it can be uploaded to the Data Repository service by creating a draft deposit and adding files and metadata. This page will guide you through the creation process of a new draft deposits, preparing and finally publishing it as a deposit. It covers:
The creation of a new draft deposit,
The addition and removal of files and metadata, and
Committing the draft deposit to publish it
Please note that the Data Repository service makes a distinction between the two terms deposit and draft deposit (or simply draft). A deposit is published and therefore unchangeable and has persistent identifiers (PID) assigned to it, as well as checksums. A user can create a deposit by first creating a draft deposit, which is modifiable. Files and metadata can be placed into a draft deposit, but not into an already published deposit.
The requests in the steps described will communicate with the training instance of the Data Repository service: https://trng-repository.surfsara.nl. Make sure to create a token in this instance of the Data Repository.
Tools
In the descriptions of each step of the workflow, the programming language Python is used. Any language or tool that supports HTTP protocol methods can be used instead. Examples are cURL or wget.
Deposit workflow
In the following diagram the general deposit workflow of Data Repository is shown. All blue boxes require a request interaction with the Data Repository service.
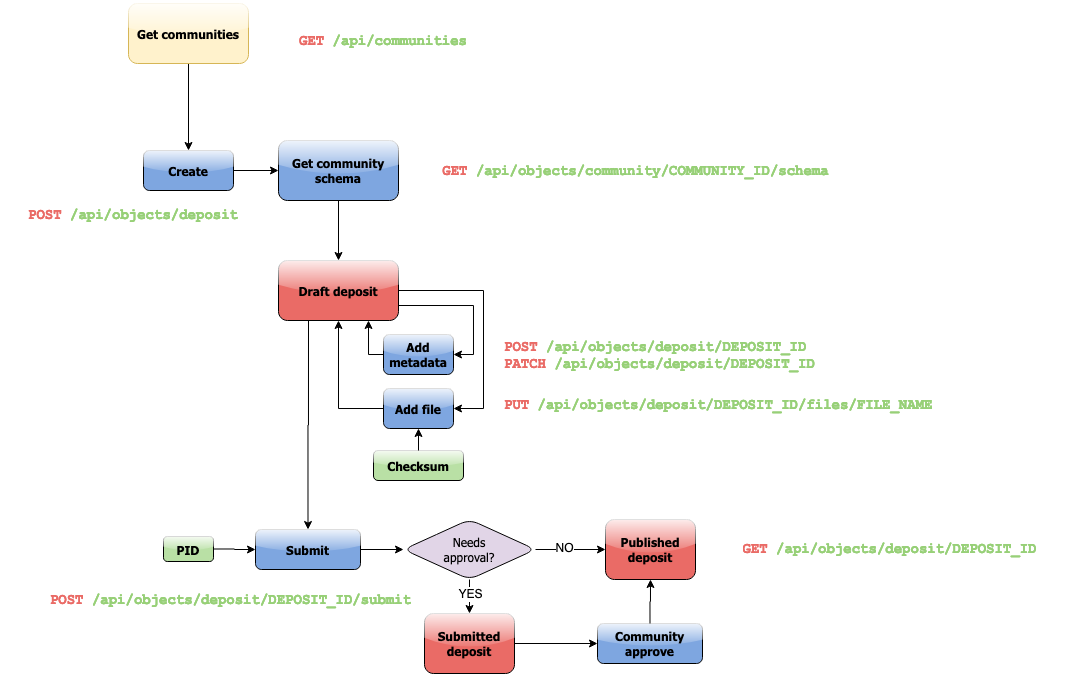
The red boxes indicate an object state, where in this workflow only draft, submitted and published deposits exist. Files and metadata can be added multiple times. Persistent identifiers (PIDs) and checksum are automatically added by Data Repository (green boxes). Once a draft deposit is committed, depending on the community’s requirements, the deposit is either in submitted state and needs further approval or is immediately published.
Create a new draft deposit
After loading your token a POST request will create a new draft deposit. Only some basic metadata is needed, like the title and community, which is sent along with the request as the data argument together with a header defining the content type. All metadata can be changed later during the deposit workflow.
In the following example, a new open access deposit is created for the SURF community with the title ‘My first upload’. The community is identified using its unique identifier:
>>> header = {"Content-Type": "application/json"}
>>> metadata = {"title": "My first upload",
"community": "community:surf",
"sharelevel": "Open"}
>>> r = requests.post('https://trng-repository.surfsara.nl/api/objects/deposit', params={'token': token}, data=json.dumps(metadata), headers=header)
On success, the response status code and text will be different this time:
{
"$schema": "https://trng-repository.surfsara.nl/static/schemas/object-metadata",
"id": "bd387af9afe48d0a",
"created": "2021-03-10T20:05:43.250000Z",
"updated": "2021-03-10T20:05:43.250000Z",
"properties": {
"namespace": "deposit",
"pid": "deposit:bd387af9afe48d0a",
"type": "deposit",
"state": "draft",
"sharelevel": "open",
"owner": "user:86"
},
"links": {
"self": "https://trng-repository.surfsara.nl/api/objects/deposit/bd387af9afe48d0a",
"landing": "https://trng-repository.surfsara.nl/deposit/bd387af9afe48d0a",
"relationships": {
"community": "https://trng-repository.surfsara.nl/api/objects/community/surf"
}
},
"metadata": {
"base": {
"$schema": "https://trng-repository.surfsara.nl/api/objects/schema/dublin",
"title": "My dataset deposit",
"rights": [
"info:eu-repo/semantics/openAccess"
]
}
}
}
Response code 201 indicates the draft deposit has been successfully created. The deposit identifier metadata field id in the response text is used to identify the draft deposit during the additional steps of adding files and metadata:
>>> result = r.json()
>>> depositid = result["pid"].split(':')[1]
>>> print(depositid)
bd387af9afe48d0a
The deposit is still in a draft state, as is indicated in the state property:
>>> print(result["properties"]["state"])
draft
After creation, the next steps are to add files and metadata. This can be done in any order and repeatedly after each addition until the draft deposit is finally published. In the next sections, both procedures are explained.
Please note that the deposit identifier will remain the same during the draft stage and after finally publishing the deposit. There is no attached EPIC PID or DOI yet.
Add files to your new draft deposit
After creation of the draft deposit, files can be added. This is achieved in a similar way as the previous example via a PUT request. Make sure your data files are accessible in the Python session. In this case the files named sequence.txt and sequence2.txt are added to the draft deposit. For every file to add to the deposit, a separate request is required.
First, define a file open handle to send along with the request, e.g. for the sequence.txt file:
>>> filename = 'sequence.txt'
>>> upload_file = open(filename, 'rb')
In this statement, the action of reading the file is not actually performed. The file will be read only when the request is done and send as a direct data stream.
Define the request URL by adding the file bucket identifier to the files end point and define the request header:
>>> url = 'https://trng-repository.surfsara.nl/api/objects/deposit/' + depositid + '/files/' + filename
>>> params = {'token': token}
>>> header = {"Content-Type": "application/octet-stream"}
The complete put request looks as follows:
r = requests.put(url, data=upload_file, params=params, headers=header)
If the request is successful, the result can be checked:
>>> print(r.status_code)
200
>>> result = json.loads(r.text)
>>> print(json.dumps(result, indent=4))
{
"$schema": "https://trng-repository.surfsara.nl/static/schemas/object-metadata",
"id": "bd387af9afe48d0a",
"created": "2021-03-10T20:05:43.250000Z",
"updated": "2021-03-10T20:09:30.379000Z",
"properties": {
"namespace": "deposit",
"pid": "deposit:bd387af9afe48d0a",
"type": "deposit",
"state": "draft",
"sharelevel": "open",
"owner": "user:86"
},
"files": [
{
"name": "sequence.txt",
"url": "https://trng-repository.surfsara.nl/deposit/bd387af9afe48d0a/files/sequence.txt",
"external": false,
"size": 691,
"mimetype": "text/plain",
"md5": "",
"epicpid": "21.T12996/5ddde41c-a461-a861-45fd-76594f2b5a20"
}
],
"links": {
"self": "https://trng-repository.surfsara.nl/api/objects/deposit/bd387af9afe48d0a",
"landing": "https://trng-repository.surfsara.nl/deposit/bd387af9afe48d0a",
"relationships": {
"community": "https://trng-repository.surfsara.nl/api/objects/community/surf"
},
"files": "https://trng-repository.surfsara.nl/api/objects/deposit/bd387af9afe48d0a/files"
},
"metadata": {
"base": {
"$schema": "https://trng-repository.surfsara.nl/api/objects/schema/dublin",
"title": "My dataset deposit",
"rights": [
"info:eu-repo/semantics/openAccess"
]
}
}
}
The mime-type is detected, direct links are given and a checksum is calculated. As soon as this checksum is ready, it will be added to the metadata of the deposit.
If the request fails, check the error by displaying the response text, for example when the files object has errors. The reponse text will, in this case, a HTML page describing the error.
When the upload file is not accessible:
>>> print(r.status_code)
400
>>> result = json.loads(r.text)
>>> print(json.dumps(result, indent=4))
{
"error": "File not found"
}
Repeat the above steps to add other files.
Check your uploaded files
When all your files have been uploaded, you can check the draft deposit’s current status regarding these files using the URL with a GET request:
>>> r = requests.get('https://trng-repository.surfsara.nl/api/objects/deposit/' + depositid + '/files', params=params)
>>> result = json.loads(r.text)
>>> print(json.dumps(result, indent=4))
[
{
"name": "sequence.txt",
"url": "https://trng-repository.surfsara.nl/deposit/bd387af9afe48d0a/files/sequence.txt",
"external": false,
"size": 691,
"mimetype": "text/plain",
"checksums": {
"md5": ""
}
"identifiers": {
"epicpid": "21.T12996/5ddde41c-a461-a861-45fd-76594f2b5a20"
}
}
]
The links to the file bucket is displayed, as well as the ‘contents’ list of two files, including the files’ sizes. You can do this with every file bucket, as long as you have the file bucket identifier.
Delete a file from a draft deposit
In case you’ve uploaded the wrong file to a draft deposit, you can delete this file as long as the deposit is in draft state. Data Repository supports deletion of files in draft deposits by the owner of that deposit or the site administrator.
In order to delete a file from a draft deposit, a request header and your access token are required:
>>> header = {"Content-Type": 'application/json'}
>>> params = {"token": token}
To make the request, the identifier of the draft deposit and the file name under which you’ve stored the file are required. Along with the DELETE request operation with the /api/objects/deposit/<depositid>/files/<file_name> endpoint in the URL, the request then looks as follows:
>>> url = "https://trng-repository.surfsara.nl/api/objects/deposit/bd387af9afe48d0a/files/sequence.txt"
>>> r = requests.delete(url, params=params, headers=header)
On a successful request, the response code should be 204 while there is no response message:
>>> print(r)
<Response [204]>
>>> print(r.text)
Add metadata to your draft deposit
Metadata is already added to a draft deposit while creating the initial deposit. By issuing a HTTP patch request with a JSON patch list of operations the current metadata of a deposit can be updated with additional or updated metadata fields and corresponding values.
To update a draft deposit’s metadata, the deposit identifier is required while making patch requests. The procedure can be applied to either draft or published deposits.
Prepare your new metadata
An object with the new and updated metadata fields and values needs to be constructed. As the community, title and share level fields have already been set when the draft deposit was created, only some missing fields are provided:
>>> metadata = {"creator": "Researcher 1",
"description": "My first dataset ingested using the Data Repository API",
"rights": "CC-0-BY"}
To update community- or collection-specific metadata fields, some additional information needs to be provided. Furthermore, to add or remove an item of a list of value, the JSON Patch requires specific paths.
Create a JSON patch
The metadata update call is made using a patch request containing the patch operations and headers. Note that:
The metadata updates for the deposit must be provided in the JSON patch format in order to avoid to have to send all the existing metadata as well
The patch format contains one or more JSONPath strings. The root of these paths is the metadata object, as this is the only mutable object
In order to successfully update the metadata, a JSON patch is created using the jsonpatch Python package. First, the original existing metadata of the deposit is retrieved which will later be altered:
>>> url = "https://trng-repository.surfsara.nl/api/objects/deposit/" + depositid
>>> r = requests.get(url, params=params)
>>> result = json.loads(r.text)
>>> metadata_old = result["metadata"]
>>> print(json.dumps(metadata_old, indent=4))
{
"base": {
"$schema": "https://trng-repository.surfsara.nl/api/objects/schema/dublin",
"title": "My dataset deposit",
"rights": [
"info:eu-repo/semantics/openAccess"
]
}
}
The actual JSON patch is created by:
>>> import jsonpatch
>>> patch = jsonpatch.make_patch(metadata_old, metadata)
>>> print(patch)
[{"path": "/titles", "op": "remove"}, {"path": "/$schema", "op": "remove"}, {"path": "/publisher", "value": "EUDAT", "op": "add"}, {"path": "/descriptions", "value": [{"description": "My first dataset ingested using the Data Repository API", "description_type": "Abstract"}], "op": "add"}, {"path": "/language", "value": "en_GB", "op": "add"}]
The current patch will remove any existing fields not present in the new metadata object, therefore these need to be removed in the final patch:
>>> finpatch = filter(lambda x: x["op"] != "remove", patch)
>>> print(list(finpatch))
[{u'path': u'/publisher', u'value': 'SURF', u'op': u'add'}, {u'path': u'/descriptions', u'value': [{'description': 'My first dataset ingested using the Data Repository API', 'description_type': 'Abstract'}], u'op': u'add'}, {u'path': u'/language', u'value': 'en_GB', u'op': u'add'}]
The patch needs to be provided to the data argument as a serialized string for which the JSON package can be used:
>>> strpatch = json.dumps(list(finpatch))
>>> print(strpatch)
[{"path": "/publisher", "value": "SURF", "op": "add"}, {"path": "/descriptions", "value": [{"description": "My first dataset ingested using the Data Repository API", "description_type": "Abstract"}], "op": "add"}, {"path": "/language", "value": "en_GB", "op": "add"}]
This section does not address the altering of community-specific metadata fields and multivalue fields.
Submit the patch
The serialized JSON patch is sent to the service in order to update the metadata.
First, the request headers need to be defined:
>>> headers = {'Content-Type': 'application/json-patch+json'}
Now, the request response text shows the updated metadata:
>>> url = 'https://trng-repository.surfsara.nl/api/objects/deposit/' + depositid
>>> r = requests.patch(url, data=strpatch, params=params, headers=headers)
>>> print(r)
<Response [200]>
>>> result = json.loads(r.text)
>>> print(json.dumps(result, indent=4))
{
"$schema": "https://trng-repository.surfsara.nl/static/schemas/object-metadata",
"id": "bd387af9afe48d0a",
"created": "2021-03-10T20:05:43.250000Z",
"updated": "2021-03-10T20:21:30.379000Z",
"properties": {
"namespace": "deposit",
"pid": "deposit:bd387af9afe48d0a",
"type": "deposit",
"state": "draft",
"sharelevel": "open",
"owner": "user:86"
},
"files": [
{
"name": "sequence.txt",
"url": "https://trng-repository.surfsara.nl/deposit/bd387af9afe48d0a/files/sequence.txt",
"external": false,
"size": 691,
"mimetype": "text/plain",
"md5": "",
"epicpid": "21.T12996/5ddde41c-a461-a861-45fd-76594f2b5a20"
}
],
"links": {
"self": "https://trng-repository.surfsara.nl/api/objects/deposit/bd387af9afe48d0a",
"landing": "https://trng-repository.surfsara.nl/deposit/bd387af9afe48d0a",
"relationships": {
"community": "https://trng-repository.surfsara.nl/api/objects/community/surf"
},
"files": "https://trng-repository.surfsara.nl/api/objects/deposit/bd387af9afe48d0a/files"
},
"metadata": {
"base": {
"$schema": "https://trng-repository.surfsara.nl/api/objects/schema/dublin",
"title": "My dataset deposit",
"rights": [
"info:eu-repo/semantics/openAccess"
]
}
}
Compare the created and updated metadata timestamp:
>>> print(result["created"], result["updated"])
2017-03-02T16:34:26.383505+00:00 2017-03-02T17:03:37.500387+00:00
In case the patch request did not succeed (status code 400), an error description containing all errors is returned in the request response text. For example, the creators field value needs to be an array:
>>> patch = '[{"path": "/creator", "value": "Data Repository author", "op": "add"}]'
>>> r = requests.patch(url, data=patch, params=params, headers=headers)
>>> print(r.status_code)
400
>>> print(r.text)
{"message": "Validation error.", "status": 400, "errors": [{"message": "'Data Repository author' is not of type 'array'", "field": "creators"}]}
Add references to external files to your draft deposit
It is possible to add files to a deposit that are not stored in the Data Repository, but this is not recommended due to the fact that Data Repository cannot guarantee the existence of the files at an external location. Although EPIC PIDs must be used to reference to these files, Data Repository cannot manage or update these PIDs when necessary. The service will also not generate these PIDs as needed, this is left to the user.
Externally referenced files are not added as files, but as separate metadata and therefore need to be provided as a JSON Patch.
If you have a list of files that can be accessed using an EPIC PID, add these files to the file listing of the Data Repository deposit. For example, if two files are added, the list must be defined as follows:
>>> external_files = [{
"name": "file1.csv",
"epicpid": "prefix/suffix1"
},
{
"name": "file2.txt",
"epicpid": "prefix/suffix2"
}]
Using this list, send the list in JSON format as described in Add externally referenced files to draft deposit.
Publishing your draft deposit
The final step will complete the draft deposit submitting it with a post request. After this request, the files of the deposit are immutable and your deposit is published!
The final commit request will return the final deposit metadata in case the request is successful (status code 200):
>>> url = "https://trng-repository.surfsara.nl/api/objects/deposit/" + depositid + "/submit"
>>> r = requests.post(url, params=params)
>>> print(r)
<Response [200]>
>>> result = json.loads(r.text)
>>> print(json.dumps(result, indent=4))
Your draft deposit is now published and is available under the REST API URL https://trng-repository.surfsara.nl/api/objects/deposit/bd387af9afe48d0a!
An EPIC persistent identifier and DOI (epicpid and doi fields) have been automatically generated and added to the metadata.
Check and display your results
Once the deposit process is completed, the results can be checked by requesting the deposit data using the new deposit identifier. Check out the deposit retrieval request for an extensive description on how to do this.
The deposit identifier id in the response message can directly be used to see the landing page of the newly created deposit: bd387af9afe48d0a. If the page displays a restriction message, this is due the server-side processing of the ingestion. As soon as this is finished, the message will disappear.
Unfortunately, some of the metadata schema fields are missing since during the metadata update step, these fields were not added to the patch. It is highly recommended to complete all fields during this step in order to increase the discoverability, authenticity and reusability of the dataset. Please check the Update metadata of draft deposit reference to update the metadata of your published deposit.